High Availability in Storage why is it so important
For anyone aspiring for a job in storage industry this is a very important concept which he needs to gain expertise in. Because HA is very very much essential in storage. Email roger.smithson@gmail.com for a FREE SAN Tutorial PDF and also FREE HA-in-Storage PDF - Email me so I can help you in your Job Hunt or any Career plans.
HA is the process of making sure your system whether it is a Single critical production server or a cluster of servers with the interconnecting network is Highly Available, round the clock 24 Hours X 7 days X 365 days usually referred as 24X7 HA.
An integral part of building large-scale, mission-critical systems that your business and your users can rely on is to ensure that no single point of failure can render a
server or network unavailable. There are several types of failures you must plan against to keep your system highly available.
Storage failures
There are many ways to protect against failures of individual storage devices using techniques such as Redundant Array of Independent Disks (RAID). Hardware solutions that support many different types of hardware redundancy for storage devices, allowing devices as well as individual components in the storage controller itself to be exchanged without losing access to the data. Software solutions also provide similar capabilities of storage redundancy.
Courtesy: Zibiz.com : Zistor Business continuity system
Network failures
There are many components to a computer network, and there are many typical network topologies that provide highly available connectivity. All types of networks need to be considered, including client access networks and management networks. In storage area networks (SANs), failures might include the storage fabrics that link the computers to the storage units.
Courtesy: ICANN.org : Database Operations (Storage Failure)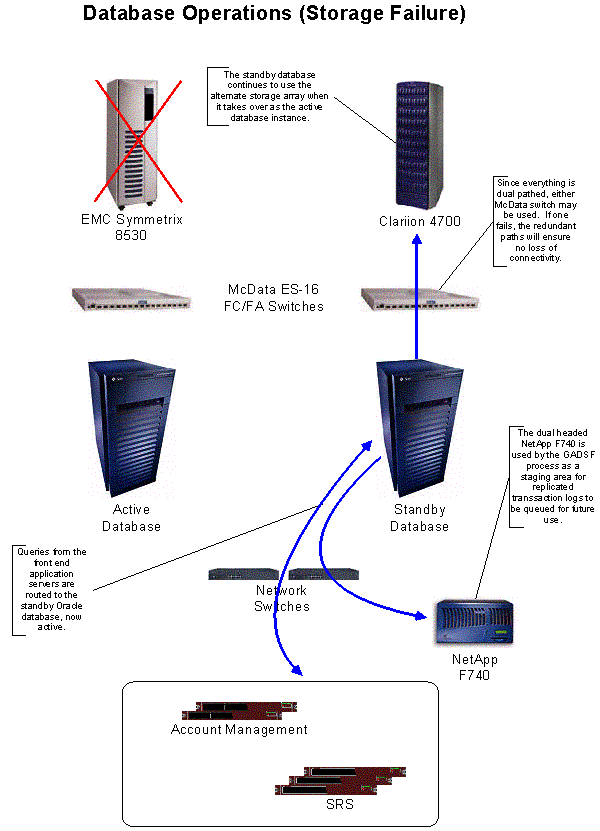
Computer or Server failures
Many enterprise-level server platforms provide redundancy inside the computer itself, such as through redundant power supplies and fans. Vendors allow components such as peripheral component interconnect (PCI) cards and memory to be swapped in and out without removing the computer from service. In cases where a computer fails or needs to be taken out of service for routine maintenance or upgrades, clustering provides redundancy to enable applications or services to continue. This redundancy happens automatically in clustering, either through failover of the application (transferring client requests from one computer to another) or by having multiple instances of the same application available for client requests.
Courtesy: Falconstor.com : Nearline Storage to Maximize Availability in a Data Center 
Site failures
In extreme cases, a complete site can fail due to a total power loss, a natural disaster, or other unusual occurrences. More and more businesses are recognizing the value of deploying mission-critical solutions across multiple geographically dispersed sites. For disaster tolerance, a data center’s hardware, applications, and data can be duplicated at one or more geographically remote sites. If one site fails, the other sites continue offering service until the failed site is repaired. Sites can be active-active, where all sites carry some of the load, or active-passive, where one or more sites are on standby.
Plz keep coming back because this blog will be updated daily twice for more information on Storage area networking or Simply Storage jobs information.











No comments:
Post a Comment